Understand Kubernetes Scheduling
What is Kubernetes Scheduling?
- The Kubernetes Scheduler is a core component of Kubernetes: After a user or a controller creates a Pod, the Kubernetes Scheduler, monitoring the Object Store for unassigned Pods, will assign the Pod to a Node. Then, the Kubelet, monitoring the Object Store for assigned Pods, will execute the Pod.
what is the scheduler for?
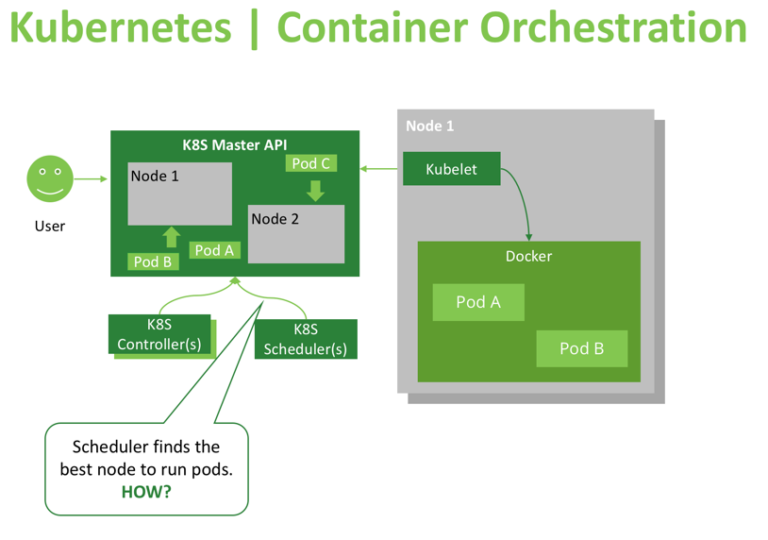
The Kubernetes scheduler is in charge of scheduling pods onto nodes. Basically it works like this:
- You create a pod
- The scheduler notices that the new pod you created doesn’t have a node assigned to it
- The scheduler assigns a node to the pod
It’s not responsible for actually running the pod – that’s the kubelet’s job. So it basically just needs to make sure every pod has a node assigned to it. Easy, right?
Kubernetes in general has this idea of a “controller”. A controller’s job is to:
- look at the state of the system
- notice ways in which the actual state does not match the desired state (like “this pod needs to be assigned a node”)
- repeat
The scheduler is a kind of controller. There are lots of different controllers and they all have different jobs and operate independently.
How Kubernetes Selects The Right node?
What is node affinity ?
- In simple words this allows you to tell Kubernetes to schedule pods only to specific subsets of nodes.
- The initial node affinity mechanism in early versions of Kubernetes was the nodeSelector field in the pod specification. The node had to include all the labels specified in that field to be eligible to become the target for the pod.
nodeSelector
Steps

apiVersion: v1 #version of the API to use
kind: Pod #What kind of object we're deploying
metadata: #information about our object we're deploying
name: nginx #Name of the pod
labels: #A tag on the pod created
env: test
spec: #specifications for our object
containers:
- name: nginx #the name of the container within the pod
image: nginx #which container image should be pulled
imagePullPolicy: IfNotPresent #image pull policy
nodeSelector: #Nodeselector condition
mynode: worker-1 # label on the node where pod is going to deploy
$ kubectl label nodes node2 mynode=worker-1
$ kubectl apply -f pod-nginx.yaml
- We have label on the node with node name,in this case i have given node2 as mynode=worker-1 label.
Viewing Your Pods
$ kubectl get pods --output=wide
$ kubectl describe po nginx
Name: nginx
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: node2/192.168.0.17
Start Time: Mon, 30 Dec 2019 16:40:53 +0000
Labels: env=test
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"labels":{"env":"test"},"name":"nginx","namespace":"default"},"spec":{"contai...
Status: Pending
IP:
Containers:
nginx:
Container ID:
Image: nginx
Image ID:
Port: <none>
Host Port: <none>
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-qpgxq (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-qpgxq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-qpgxq
Optional: false
QoS Class: BestEffort
Node-Selectors: mynode=worker-1
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7s default-scheduler Successfully assigned default/nginx to node2
Normal Pulling 3s kubelet, node2 Pulling image "nginx"
[node1 Scheduler101]$
- You can check in above output Node-Selectors: mynode=worker-1
Deleting the Pod
$ kubectl delete -f pod-nginx.yaml
pod "nginx" deleted
Node affinity
-
Node affinity is conceptually similar to nodeSelector – it allows you to constrain which nodes your pod is eligible to be scheduled on, based on labels on the node.
-
There are currently two types of node affinity.
- requiredDuringSchedulingIgnoredDuringExecution (Preferred during scheduling, ignored during execution; we are also known as “hard” requirements)
- preferredDuringSchedulingIgnoredDuringExecution (Required during scheduling, ignored during execution; we are also known as “soft” requirements)
Steps
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: mynode
operator: In
values:
- worker-1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: mynode
operator: In
values:
- worker-3
containers:
- name: nginx
image: nginx
$ kubectl label nodes node2 mynode=worker-1
$ kubectl label nodes node3 mynode=worker-3
$ kubectl apply -f pod-with-node-affinity.yaml
Viewing Your Pods
$ kubectl get pods --output=wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
with-node-affinity 1/1 Running 0 9m46s 10.44.0.1 kube-slave1 <none> <none>
$ kubectl describe po
Name: with-node-affinity
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: node3/192.168.0.16
Start Time: Mon, 30 Dec 2019 19:28:33 +0000
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"name":"with-node-affinity","namespace":"default"},"spec":{"affinity":{"nodeA...
Status: Pending
IP:
Containers:
nginx:
Container ID:
Image: nginx
Image ID:
Port: <none>
Host Port: <none>
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-qpgxq (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-qpgxq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-qpgxq
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 26s default-scheduler Successfully assigned default/with-node-affinity to node3
Normal Pulling 22s kubelet, node3 Pulling image "nginx"
Normal Pulled 20s kubelet, node3 Successfully pulled image "nginx"
Normal Created 2s kubelet, node3 Created container nginx
Normal Started 0s kubelet, node3 Started container nginx
Step Cleanup
Finally you can clean up the resources you created in your cluster:
$ kubectl delete -f pod-with-node-affinity.yaml
Anti-Node Affinity ?
- Some scenarios require that you don’t use one or more nodes except for particular pods. Think of the nodes that host your monitoring application.
- Those nodes shouldn’t have many resources due to the nature of their role. Thus, if other pods than those which have the monitoring app are scheduled to those nodes, they hurt monitoring and also degrades the application they are hosting.
- In such a case, you need to use node anti-affinity to keep pods away from a set of nodes.
Steps
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: mynode
operator: In
values:
- worker-1
- key: mynode
operator: NotIn
values:
- worker-3
containers:
- name: nginx
image: nginx
$ kubectl label nodes node2 mynode=worker-1
$ kubectl label nodes node3 mynode=worker-3
$ kubectl apply -f pod-anti-node-affinity.yaml
Viewing Your Pods
$ kubectl get pods --output=wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 2m37s 10.44.0.1 node2 <none> <none>
Get nodes label detail
$ kubectl get nodes --show-labels | grep mynode
node2 Ready <none> 166m v1.14.9 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux,mynode=worker-1,role=dev
node3 Ready <none> 165m v1.14.9 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node3,kubernetes.io/os=linux,mynode=worker-3
Get pod describe
$ kubectl describe pods nginx
Name: nginx
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: node2/192.168.0.17
Start Time: Mon, 30 Dec 2019 19:02:46 +0000
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"name":"nginx","namespace":"default"},"spec":{"affinity":{"nodeAffinity":{"re...
Status: Running
IP: 10.44.0.1
Containers:
nginx:
Container ID: docker://2bdc20d79c360e1cd857eeb9bbb9424c726b2133e78f25bf4587e0befe3fbcc7
Image: nginx
Image ID: docker-pullable://nginx@sha256:b2d89d0a210398b4d1120b3e3a7672c16a4ba09c2c4a0395f18b9f7999b768f2
Port: <none>
Host Port: <none>
State: Running
Started: Mon, 30 Dec 2019 19:03:07 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-qpgxq (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-qpgxq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-qpgxq
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 60s default-scheduler Successfully assigned default/nginx to node2
Normal Pulling 56s kubelet, node2 Pulling image "nginx"
Normal Pulled 54s kubelet, node2 Successfully pulled image "nginx"
Normal Created 40s kubelet, node2 Created container nginx
Normal Started 39s kubelet, node2 Started container nginx
- Adding another key to the matchExpressions with the operator NotIn will avoid scheduling the nginx pods on any node labelled worker-1.
Step Cleanup
Finally you can clean up the resources you created in your cluster:
$ kubectl delete -f pod-anti-node-affinity.yaml
What is Node taints and tolerations ?
-
This Kubernetes feature allows users to mark a node (taint the node) so that no pods can be scheduled to it, unless a pod explicitly tolerates the taint.
-
When you taint a node, it is automatically excluded from pod scheduling. When the schedule runs the predicate tests on a tainted node, they’ll fail unless the pod has toleration for that node.
-
Like last monitoring example: Let assume new member joins the development team, writes a Deployment for her application, but forgets to exclude the monitoring nodes from the target nodes? Kubernetes administrators need a way to repel pods from nodes without having to modify every pod definition.
Steps
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- dev
containers:
- name: nginx
image: nginx
$ kubectl label nodes node2 role=dev
$ kubectl label nodes node3 role=dev
$ kubectl taint nodes node2 role=dev:NoSchedule
node/node2 tainted
$ kubectl apply -f pod-taint-node.yaml
Viewing Your Pods
$ kubectl get pods --output=wide
Get nodes label detail
[node1 Scheduler101]$ kubectl get nodes --show-labels|grep mynode |grep role
node2 Ready <none> 175m v1.14.9 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux,mynode=worker-1,role=dev
node3 Ready <none> 175m v1.14.9 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node3,kubernetes.io/os=linux,mynode=worker-3,role=dev
Get pod describe
$ kubectl describe pods nginx
Name: nginx
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: node3/192.168.0.16
Start Time: Mon, 30 Dec 2019 19:13:45 +0000
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"name":"nginx","namespace":"default"},"spec":{"affinity":{"nodeAffinity":{"re...
Status: Running
IP: 10.36.0.1
Containers:
nginx:
Container ID: docker://57d032f4358be89e2fcad7536992b175503565af82ce4f66f4773f6feaf58356
Image: nginx
Image ID: docker-pullable://nginx@sha256:b2d89d0a210398b4d1120b3e3a7672c16a4ba09c2c4a0395f18b9f7999b768f2
Port: <none>
Host Port: <none>
State: Running
Started: Mon, 30 Dec 2019 19:14:45 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-qpgxq (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-qpgxq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-qpgxq
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 105s default-scheduler Successfully assigned default/nginx to node3
Normal Pulling 101s kubelet, node3 Pulling image "nginx"
Normal Pulled 57s kubelet, node3 Successfully pulled image "nginx"
Normal Created 47s kubelet, node3 Created container nginx
Normal Started 45s kubelet, node3 Started container nginx
- Deployed pod on node3.
Step Cleanup
Finally you can clean up the resources you created in your cluster:
$ kubectl delete -f pod-tain-node.yaml
Tolerations
- A toleration is a way of ignoring a taint during scheduling. Tolerations aren’t applied to nodes, but rather the pods. So, in the example above, if we apply a toleration to the PodSpec, we could “tolerate” the slow disks on that node and still use it.
Steps
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx:1.7.9
imagePullPolicy: IfNotPresent
tolerations:
- key: "role"
operator: "Equal"
value: "dev"
effect: "NoSchedule"
$ kubectl apply -f pod-tolerations-node.yaml
Viewing Your Pods
$ kubectl get pods --output=wide
Which Node Is This Pod Running On?
$ kubectl describe pods nginx
Name: nginx
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: node3/192.168.0.16
Start Time: Mon, 30 Dec 2019 19:20:35 +0000
Labels: env=test
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"labels":{"env":"test"},"name":"nginx","namespace":"default"},"spec":{"contai...
Status: Pending
IP:
Containers:
nginx:
Container ID:
Image: nginx:1.7.9
Image ID:
Port: <none>
Host Port: <none>
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-qpgxq (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-qpgxq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-qpgxq
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
role=dev:NoSchedule
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 4s default-scheduler Successfully assigned default/nginx to node3
Normal Pulling 1s kubelet, node3 Pulling image "nginx:1.7.9
Step Cleanup
Finally you can clean up the resources you created in your cluster:
$ kubectl delete -f pod-tolerations-node.yaml
- An important thing to notice, though, is that tolerations may enable a tainted node to accept a pod but it does not guarantee that this pod runs on that specific node.
- In other words, the tainted node will be considered as one of the candidates for running our pod. However, if another node has a higher priority score, it will be chosen instead. For situations like this, you need to combine the toleration with nodeSelector or node affinity parameters.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.